
Große Daten
So wählen Sie den Clustering-Algorithmus richtig aus
Clustering-Algorithmen umfassen hierarchisches Clustering und schwerpunktbasiertes Clustering. Und maximaler Erwartungsalgorithmus, dichtebasierter Clustering-Algorithmus. Jedes hat seine eigenen Vorteile und Schwächen. Sie werden in unterschiedlichen Arbeitsumgebungen eingesetzt. Es ist nicht einfach, den richtigen Clustering-Algorithmus auszuwählen. Im Folgenden werden vier Mainstream-Clustering-Algorithmen in dieser Phase vorgestellt.
1. Konnektivitätsbasiertes oder hierarchisches Clustering
Eine Clustering-Methode basierend auf der Abstandsberechnung zwischen Objekten im gesamten Datensatz. Es handelt sich um konnektivitätsbasiertes Clustering oder hierarchisches Clustering. Je nach "Richtung" des Algorithmus kann er Informationen kombinieren. Und es kann wiederum Informationen zerlegen. Der beliebteste Typ ist der Cluster-Typ. Sie können mit der Eingabe aller Daten beginnen und diese Datenpunkte dann kombinieren. Werden immer größere Cluster, bis das Limit erreicht ist.
Der hierarchische Clustering-Algorithmus gibt Baumdaten zurück. Das Baumdiagramm zeigt die Struktur der Informationen. Anstatt die spezifische Sortierung auf dem Cluster. Dieser Algorithmus ist nicht für Datensätze ohne Hierarchien geeignet. Von der Standardkategorie zu allen Datenpunkten. Die Anzahl der Kategorien hat keinen wesentlichen Einfluss auf das Endergebnis. Es hat auch keinen Einfluss auf die Standardentfernungsmetrik. Grobe Messung und ungefähre Schätzung erhalten ihre Entfernungsmetrik.
2. Clusterbildung des Schwerpunkts
Centroid Clustering ist das gebräuchlichste Clustering-Modell. Seine Bedienung ist einfach. Es unterteilt jede der Datensatzarten in bestimmte Kategorien. Das größte Problem besteht darin, dass die Anzahl der Cluster (k) zufällig gewählt wird.
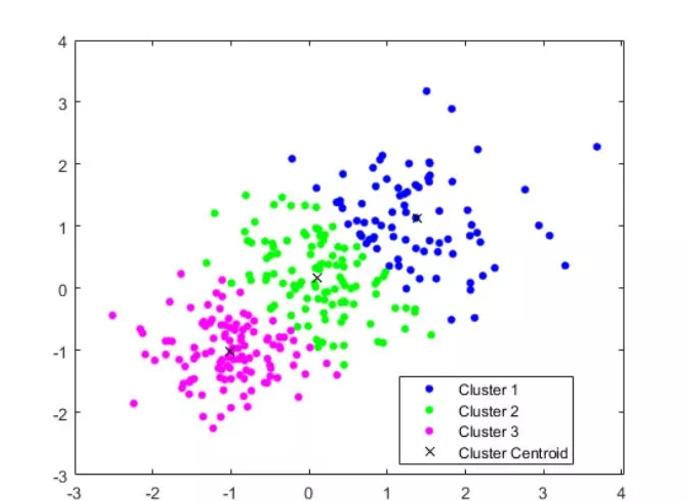
Die Mathematik und der Code des Centroid-Clustering-Algorithmus sind recht einfach. Der k-Mittelwert weist einige Mängel auf. Sie gilt nicht für alle Modelle. Seine Mängel sind wie folgt.
1) Setzen Sie Priorität auf die Mitte des Clusters, nicht auf die Grenze. Daher wird die Grenze jedes Clusters leicht vernachlässigt.
2) Kann keine Datensatzstruktur erstellen. Seine Objekte können gleichermaßen in mehrere Cluster eingeteilt werden.
3) Sie müssen die beste Anzahl von Kategorien erraten (k). Oder es ist eine erste Berechnung erforderlich, um diese Rubrik zu spezifizieren.
3. Algorithmus zur Erwartungsmaximierung
Der Erwartungsmaximierungsalgorithmus kann einige komplizierte Situationen vermeiden. Bietet eine höhere Genauigkeit. Es berechnet die zugehörige Wahrscheinlichkeit jedes Datensatzpunkts mit allen angegebenen Clustern. Das Hauptwerkzeug für dieses Clustering-Modell ist das Gaussian Mixture Model (GMM). Angenommen, die Punkte des Datensatzes gehorchen einer Gaußschen Verteilung.
4. Clustering basierend auf Datendichte
Clustering basierend auf der Datendichte ist der Favorit von Data Scientists. Der Name des Algorithmus zeigt die Hauptpunkte des Modells. Teilen Sie den Datensatz in Cluster auf. Der Zähler gibt den ε-Parameter ein, der die "Nachbar"-Distanz ist. Liegt der Zielpunkt also innerhalb eines Kreises (Kugel) mit Radius ε, gehört er zum Cluster.
Dichtebasiertes räumliches Clustering von Anwendungen mit Rauschen, das als DBSCAN bezeichnet wird. DBSCAN prüft jedes Objekt Schritt für Schritt. Ändern Sie den Status in Anzeigen. Teilen Sie es in bestimmte Kategorien oder Geräusche ein. Bis es den gesamten Datensatz verarbeitet. Von DBSCAN ermittelte Cluster können jede beliebige Form haben. Die auf diese Weise erhaltenen Ergebnisse werden genauer sein. Das auf diese Weise erhaltene Ergebnis wird genauer. Dieser Algorithmus muss die Anzahl der Cluster nicht manuell festlegen. Der Algorithmus kann automatisch entscheiden.
DBSCAN hat einige Nachteile. Wenn der Datensatz aus Clustern mit variabler Dichte besteht, sind die Ergebnisse schlecht. Wenn der Standort des Objekts zu nahe ist und die Parameter nicht einfach abgeschätzt werden können. Dann ist dies keine gute Wahl.
Das Obige führt vier Mainstream-Clustering-Algorithmen ein. Sie alle haben ihre eigene Gewissheit. Ich hoffe, Sie können den Algorithmus auswählen, der zu Ihnen passt.